



홈페이지 검색 잘 되도록 만들기

목적에 따라 다르겠지만
그래도 방문자가 있어야 홈페이지를 관리하는 재미가 있죠.
네이버 블로그 같은 경우는 글만 써도 방문자들이 있는데
개인 홈페이지는 그렇지 않습니다. 만드는 것도 쉽지 않은데 서럽네요.
위 사진은 Google 검색을 통한 3월의 페이지 방문수입니다.
계속 3명정도의 방문수를 기록하다가
Google Search Console에 sitemap 을 등록하자마자 11명으로 오른 것이 확인됩니다.
고작 하루에 11명이냐고요? 제게는 많은 발전입니다.. ㅜㅡ
홈페이지가 검색이 잘되도록 하려면 일단 Sitemap이나 RSS 가 필요하고
Googgle, Daum, Naver 같은 검색엔진에 등록을 해야합니다.
그 방법에 대해서 알아보도록 하겠습니다.
준비하기
Robots.txt 생성
robots.txt 파일에 sitemap 파일 위치를 등록해두면
검색엔진의 크롤러들이 홈페이지를 크롤링하는데 도움을 주게 됩니다.
/robots.txt 파일을 만들고 아래와 같이 입력합니다. 반드시 root 위치에 파일을 만드세요.
User-agent: *
Allow: /
Sitemap: http://dveamer.github.io/sitemap.xml
참고로
특정 검색엔진만 허용하기 위해서는 User-agent에 검색엔진 명을 넣으면 됩니다.
저는 Github-Pages 를 이용하기 때문에 별 생각없이 모든 검색엔진으로 세팅했지만
개인적으로 작은서버를 돌리시는 분은 고민이 필요하실 수도 있습니다.
예를들어 구글, 다음, 네이버, 줌만 허용하려면 아래와 같이 하시면 됩니다.
User-agent: Googlebot
User-agent: DAUMOA
User-agent: NaverBot
User-agent: ZumBot
Allow: /
Sitemap: http://dveamer.github.io/sitemap.xml
만약 크롤링 되길 원치 않는 페이지가 있다면 robots.txt파일에 Disallow: /pagename.html 을 추가해주시면 됩니다.
예를들어 http:dveamer.gihub.io/diary/ 아래의 모든 페이지의 크롤링을 원치 않는다면 아래와 같이 하면 됩니다.
User-agent: *
Allow: /
User-agent: *
Disallow: /diary/
Sitemap: http://dveamer.github.io/sitemap.xml
베드봇 차단하고 싶다면 아래와 같이 하면 됩니다.
User-agent: *
Allow: /
User-agent: BadBot
Disallow: /
Sitemap: http://dveamer.github.io/sitemap.xml
List of User-Agents
Google Search Console 등록
Sitemap 을 등록하게 됩니다.
Google Search Console 에 접속합니다.
홈페이지에 해당되는 Console을 오픈 후 크롤링 > Sitemaps 메뉴를 오픈합니다.
오른쪽 상단의 SITEMAP 추가 버튼을 누른 후 만들어두었던 sitemap.xml 파일 주소를 입력 후 제출 합니다.
제출 완료 후 화면을 새로고침 하면 sitemap.xml 파일이 등록된 것을 확인 할 수 있으며
색인이 접수 중인 것을 확인 할 수 있습니다.

시간이 지나서 색인이 처리가 되면 구글링으로 검색되어집니다.
제 경우는 “접수중” 표시가 사라질 때까지 만 2일 걸린 것 같습니다.
Daum 등록
DAUM 검색등록 에 접속 후 로그인합니다.
“등록” 탭에서 “블로그 RSS등록” 을 선택하고 “블로그 URL” 과 “블로그RSS URL” 을 입력 후 확인버튼을 클릭합니다.

Naver 등록
네이버 웹마스터 도구 에 접속합니다.
일단 로그인을 하고 사이트를 등록합니다. 그 과정에서 “사이트 소유 확인” 이라는 과정이 있습니다.
소유를 확인하면 Google Analystics 와 비슷한 서비스를 받을 것으로 예상됩니다.
저는 “사이트 소유 확인 불가” 를 선택했습니다.
그래도 RSS 등록 가능합니다.

추가 된 사이트를 클릭하시면 해당사이트의 정보가 뜹니다.
왼쪽 메뉴에서 요청 > RSS제출 을 클릭합니다.
도메인을 포함한 URL 을 입력하시고 확인 버튼을 클릭합니다.

검색 결과
첫 등록을 하고 2개월 정도 지난 시점에서 검색을 해봤습니다.
Daum 을 제외하고 Google, Naver 에서는 검색이 잘 되더군요.
Google Analytics 로 모니터링을 하고 있는데
Daum 을 통한 접근이 다른 곳에 비해 현저히 적다는 것은 알고 있었지만
Daum 사용자 수가 적어서 그런가보다 하고 있었는데.. 그게 아니었습니다.
평소 방문자가 없는 글은 검색해도 저 조차 찾을 수 없을 것 같기에..
평소 방문자가 꾸준히 있는 글을 검색해봤습니다.
근데 생각보다 상위에 검색이 되서 놀랬습니다.
대중적인 주제가 아니고, 제 글의 제목에 포함된 단어들로만 검색을 했으니 당연한 결과일 수도 있습니다.
-
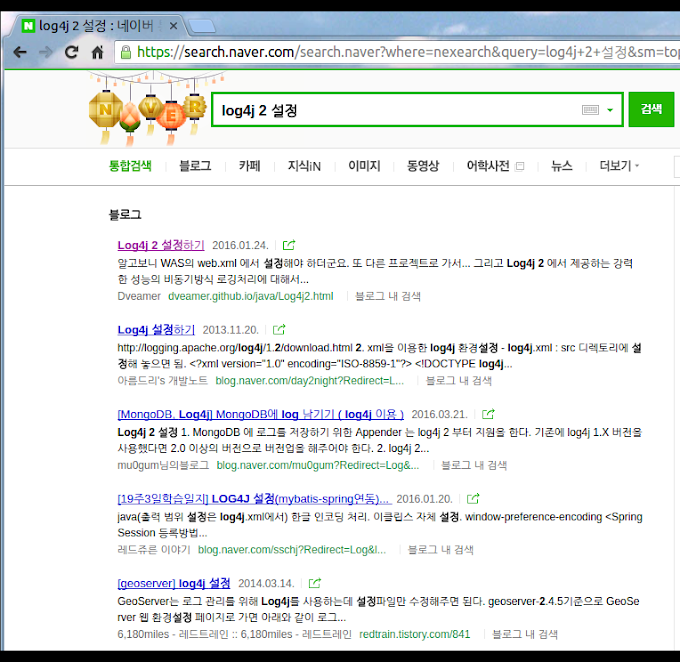
검색어 : Log4j 2 설정
검색시점 : 2016년 5월 14일
검색 결과 : 8번째
-
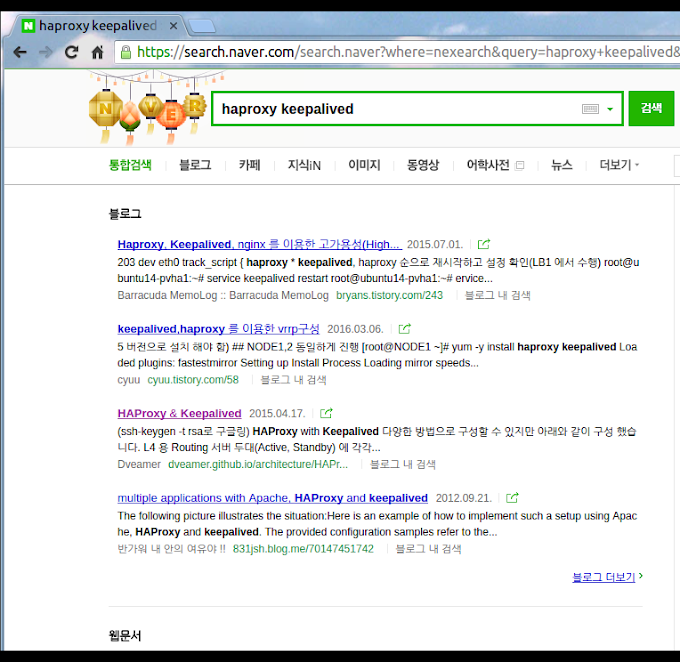
검색어 : haproxy keepalived
검색시점 : 2016년 5월 14일
검색 결과 : 2 페이지 끝에서 2번째


Daum
-
검색어 : Log4j 2 설정
검색시점 : 2016년 5월 14일
검색 결과 : 1번째
-
검색어 : haproxy keepalived
검색시점 : 2016년 5월 14일
검색 결과 : 검색 안됨

검색어를 “haproxy keepalived dveamer” 로 해봐도 검색이 안됩니다.
dveamer 로 검색해보니 딱 2개의 글만 검색이 되더군요.
검색안되는 이유는 두가지 정도로 추측해보고 있습니다.
첫번째 추측은,
글을 작성한 시점이 Daum 에 RSS 를 등록한 시점보다 더 과거인데
Daum 에서 수집하는 로직 과정에서 과거 글을 수집하지 않는 것이 아닐까? 합니다.
최근변경일자(lastmod)를 최근으로 세팅해줘야 수집이 되려나.. 추측해보고 있습니다.
“설마.. 그럴까..” 라고 생각이 들 정도로 엉뚱한 추측이지만
일단 검색이 되는 글 2개는 모두 lastmod 가 세팅되어있습니다. 좀 설득력이 있죠? ㅋ
그러나 lastmod 가 세팅된 글이 2개밖에 없는 것은 아니기 때문에.. 다시 설득력이 떨어집니다.
두번째 추측은,
robot.txt 파일에 구글, 다음, 네이버, 줌의 봇에게만 접근을 허용하도록 설정했는데
Daum User-agent 값이 잘 못들어간 것이 아닌가 추측중입니다.
2개 글이 검색되고 있다는 점에서 좀 설득력이 떨어지긴 합니다.
일단 robot.txt 를 전체 허용으로 수정하고 지켜본 후
변화가 없으면 lastmod 를 HAProxy & Keepalived 글에도 추가해보려고 합니다.
Naver
-
검색어 : Log4j 2 설정
검색시점 : 2016년 5월 14일
검색 결과 : 1번째
-
검색어 : haproxy keepalived
검색시점 : 2016년 5월 14일
검색 결과 : 3번째
Associated Posts
관련된 주제를 살펴볼 수 있도록 동일한 Tag를 가진 글들을 모아뒀습니다. 제목을 눌러주세요.-
홈페이지 현황 ( Log4J 2 관련 대박사건 )

( 이미지 출처 : https://logging.apache.org )Log4J 공식사이트- Articles and Tutorials에서 제 블로그 글을 링크 걸어두고 있던 것을 발견하여 기록합니다.
큰 의미가 있는 것은 아니지만 개인적으로 기분이 좋네요. (저한테만 대박사건 ㅋ)
... 더 읽기 -
플러그인 없이 Jekyll RSS Feed 만들기
이번 글에서는 RSS Feed 를 만들어 봅니다.
RSS는 검색 가능성을 높이기 위해 Daum, Naver 검색엔진에 등록할 때도 사용됩니다.
등록하는 과정은 홈페이지 검색 잘 되도록 만들기 에서 확인 하실 수 있습니다.... 더 읽기 -
패키지가 설치 된 위치 찾기 in Ubuntu
Windows 에서는 대부분 Program files 디렉토리에 설치가 되는 편인데
Linux 는 좀 이곳저곳에 설치되는 느낌이 강합니다.어떤 방법으로 설치하느냐에 따라서도 좀 달라지고
게다가 어떤 계정으로 설치하느냐에 따라 달라지는 것 같기도 하고요.패키지가 설치 된 디렉토리 찾는법을 알아보겠습니다.
... 더 읽기